Psychological Classification of Reddit Posts
Project Goal
Identify linguistic signals within social media posts in order to predict if a user suffers from severe psychological disorder.
Project Details
- Psychological classification of Reddit posts is a final project for the graduate course CMSC773 - Computational Linguistics II at the Universitu of Maryland - College Park.
- Languages used: Python and R
- Source code avialable at GitHub
Introduction
Mental health problems are among the costliest challenges societies are facing. Mental Health Organization (WHO) has reported that mental health illnesses are the leading cause of disability-adjusted life years worldwide. In the United States, suicide is the third leading cause of death among people of 10 to 24 years old.
Language is an important tool in diagnosing and monitoring mental health problems in patients. In this project, it was attempted to answer the question of whether identifiable linguistic signals within social media posts exist in order to predict if a user will make a suicide attempt.
Data Set
In this study, Reddit users' posts history were used and “positive” users were identified as those who have posted into the subreddit, r/suicidewatch (SW). The "positive" and "control (negative)" data were provided by the instructor. The data collection is explained by the instructor as following:
"We've created a reddit-based dataset inspired Harman et al., focusing on suicidality as the mental health condition of interest. We began by identifying users of interest using a July 2015 snapshot of every publicly available reddit posting as of that date, approximately 1.7B in all."
Therefore, to collect the data, potentially positive users were identified by users who have made any post to the /r/SuicideWatch subreddit. From the same data set a comparable number of randomly selected control users were presumed negative. Then Reddit API was used to collect all posts by positive and negative users from their earliest post up until 2016-07-14. Then the users were filtered to only include users with more than 10 posts across all Reddit.
The total Size of the data file was about 200 MB. Table 1 presents the breakdown of the number of posts for training, development, and test.

Table 1. Number of users in each set.
Methods
A random sample of 'n' users ids were chosen from both the positive and control data sets. For optimization purposes, only files containing chosen IDs were opened. After this loading step, any posts from other mental health subreddits was filtered out, since the intention was to identify features that are generalizable to other social media platforms (i.e. platforms not restricted to mental health issue), and the openness found within these subreddits is unique to Reddit. The following subreddits were specifically filtered out: Anger, BPD, EatingDisorders, MMFB, StopSelfHarm, addiction, alcoholism, depression, feelgood, gettingoverit, hardshipmates, mentalhealth, psychoticreddit, ptsd, rapecounseling, socialanxiety, survivorsofabuse, and traumatoolbox.
Each of the user’s remaining post bodies were concatenated to form a single corpus for each user. This corpus was then tokenized using the NLTK word_tokenize method, and stopwords were filtered out. Specifically, the set of stopwords included the English stopword set from NLTK, punctuation characters defined by Python’s string library, and the following stopwords added by our team: 's 're n't 'm 've 'd '' 't -- ‘’ ` ... .. ** +_ __.
Analysis
Word Classes
For word class studies, the LIWC lexicons (Pennebaker’s Linguistic Inquiry and Word Count, provided by instructor) and the MPQA lexicons (Multi Perspective Question Answering package provided via http://mpqa.cs.pitt.edu/) were considered. As mentioned by (Mowery et. al. 2017), the LIWC lexicons associated with negative emotions can be used to assess the difference between positive and control posts. The MPQA lexicons provide clues regarding polarity and subjectivity of words in sentences. The MPQA study was chosen after a suggestion by (Milne et. al. 2016), where polarity and subjectivity of a sentence can be used as features to determine the state of the mind.
The hypotheses in the word class study are as follows:
- Emotion scores calculated from the LIWC word classes are related to the state of mind of the user and therefore the likelihood of seeing a post in the SW subreddit.
- Negative polarity and subjectivity are related to the state of the mind and therefore are related to the likelihood of seeing a post in the SW subreddit.
To work with the LIWC and MPQA lexicons, both lexicons were pre-processed to generate a pair of dictionaries: one that mapped vocabulary words to LIWC classes (for the LIWC dataset) and the other which mapped each vocabulary word to a tuple of polarity and subjectivity scores (for the MPQA dataset). During training or testing time, the process of matching an arbitrary word from the post dataset to a key in one of these dictionaries, can be time-intensive since a number of lexicon keys are stored as prefix matches. Thus, for performance reasons, the post datasets were pre-processed and converted each post title and body into a comma-separated list of (LIWC class, class frequency)-tuples. Generating these converted posts took ~10 hours running on two computers.
Interesting results were discovered upon similarity check. For this purpose, random sampling was used to sample 20 positive users and 20 control users. For each user, the LIWC representation corpus was computed. Using the averaged KL-divergence equation:
D(avg) = 1/2 [D(P||Q) + D(Q||P)]
Where:
D(P(w)||Q(w)) = Sum{P(w).log[P(w)/Q(w)]}
P(w) = [f(w) + 1] / sum[f(w) + 1] = [f(w) + 1] / {Sum[f(wi)] + |V|}
P, and Q are Laplace smoothed probability distribution of the words, w, from two given users, and f is the frequency of each word in the corpus.
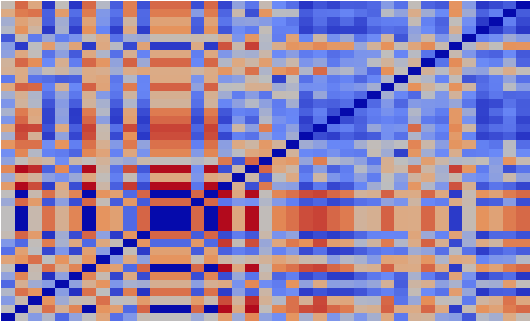
The similarity between all 40 user posts was computed. The results are presented as a heat map in Fig. 1, where blue color means the two corpora are more similar, and red means they are more dissimilar.
As we can see, there is a clear distinction between control and positive posts. Positives versus positives have a closer similarity to each other (the upper right is heavily blue) compared with the positives versus controls, and even controls versus controls. The heat map shows that controls versus controls are as dissimilar to each other as controls vs positives are. So, these results suggest that LIWC word classes may become a promising feature for supervised classification.
Figure 1. Heatmap of averaged KL Divergence showing the similarity between positives and controls user corpora. User IDs are shown on the X and Y axis, where positive numbers represent users from the positive set and negative numbers represent users from the control set.
Using the results presented in Fig. 1, a corpus of true positives (TP) formed (highest similarity positive users were chosen and their posts merged together). This corpus was then used to compute the averaged KL Divergence similarity score between the TP corpus and other positive users. The distribution of similarity score for 1000 users randomly selected from the positives is shown in Fig. 2. As it can be seen, a majority of users show very high similarity.
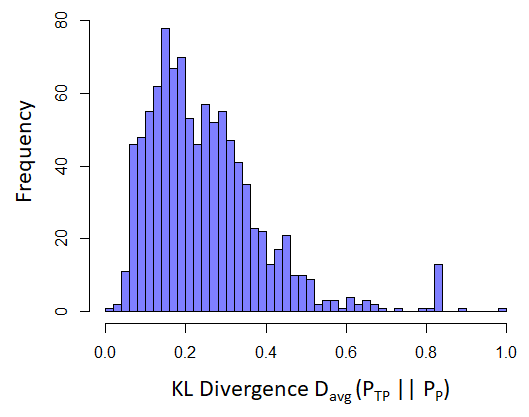
Figure 2. Histogram of averaged KL Divergence between true positive posts and randomly selected positive posts. Lower KL Divergence values indicate higher similarity.
After the initial run, the true positive user collection was updated by random selection of a few more users whose similarity score were less 0.2. Therefore, the true positive corpus now consists of 25 users. This new corpus was used to analyze the differences between positive and control posts. A similarity score distribution for 1000 positives and 1000 controls with respect to the true positive corpus is shown in Fig. 3. Furthermore, statistical analysis was performed to assess the hypothesis that the averaged KL divergence similarity score is related to the probability of the user posting in the SW subreddit. For this test, a Wilcoxon rank sum test (due to the nonnormal distribution of the scores) was used. The p-value < 2.2e-16, indicates that the relation is significant and hence we can reject the null hypothesis.
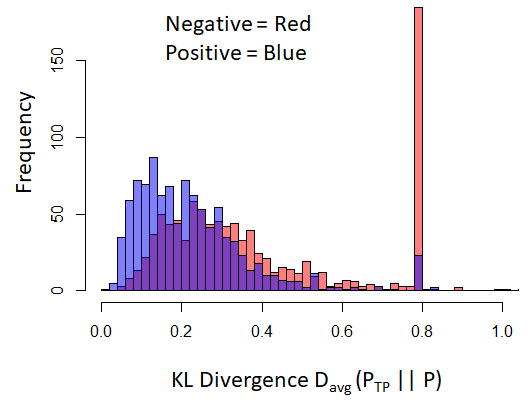
Figure 3. Histogram of averaged KL Divergence between true positive posts and randomly selected positive and controls (negative) posts. The lower number KL Divergence indicates higher similarity.
LIWC features a variety of categories of words. Two of these categories are POSEMO (positive emotion) and NEGEMO (negative emotion). We attempt to test if emotion can be captured from the positive and control posts and whether these emotion categories can serve as features. For this test, the LIWC representation of a user’s corpus was calculated, and an emotion score was assigned where each POSEMO word incremented the score by +1 and each NEGEMO word decremented the score by -1. The total emotion score then normalized over the length of the corpus. Furthermore, a negative emotion only score was considered based on only the sum of the NEGEMO scores.
For this study the null and alternative hypotheses are as following:
Null Hypothesis: Emotion score is not related to the positive or control posts.
Alternate Hypothesis: Emotion score is related to the positive and control posts.
This test was performed twice: once with only the text bodies and the second time with only the text titles. Figure 4 shows the histogram showing the frequency of emotion and negative emotion scores across a random sample of 200 positive users and 200 control users.
The results from t-test analysis (using R) on the distribution of emotion and negative emotion scores for post bodies and titles are as following:
Emotion score for post bodies : p-value = 3.54e-5
Emotion score for post titles : p-value = 0.0242
Negative emotion score for post bodies : p-value = 1.993e-8
Negative emotion score for post titles : p-value = 0.0125
Overall, we can see that all p-values are lower than 0.05, significance coefficient. Therefore, in all cases, we can reject the null hypothesis and conclude that both scores yield a statistically significant difference between positive and control posts.
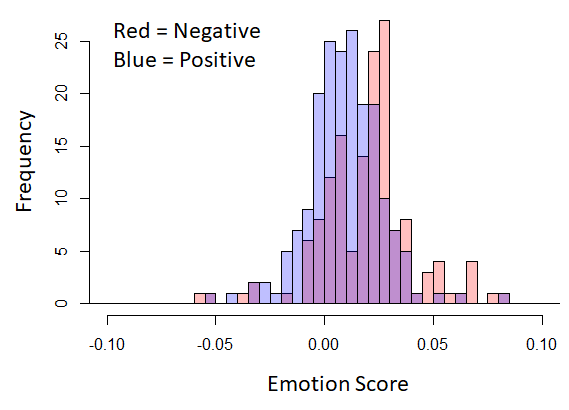
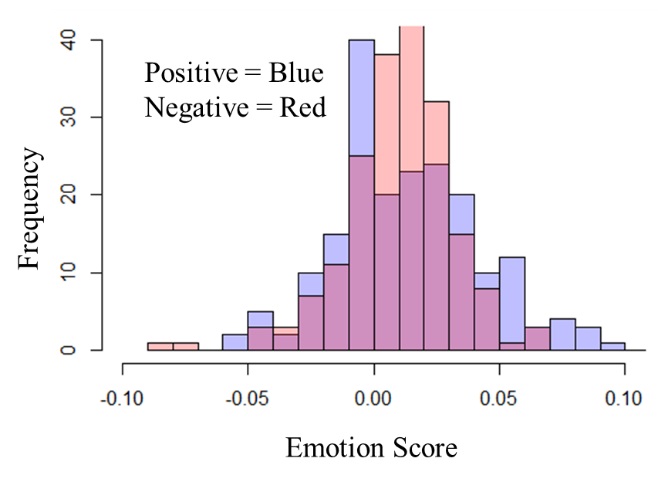
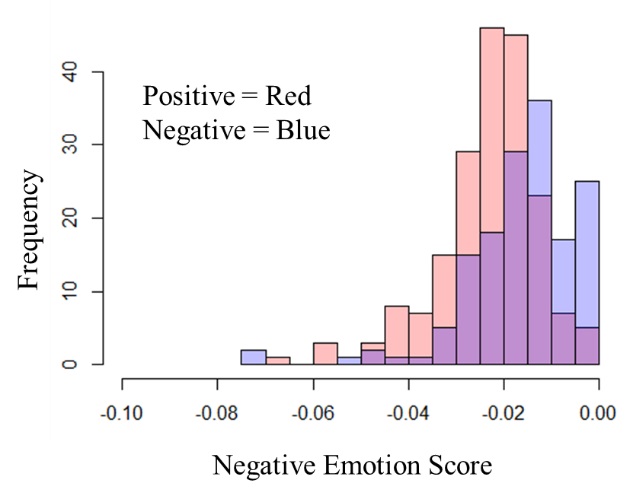
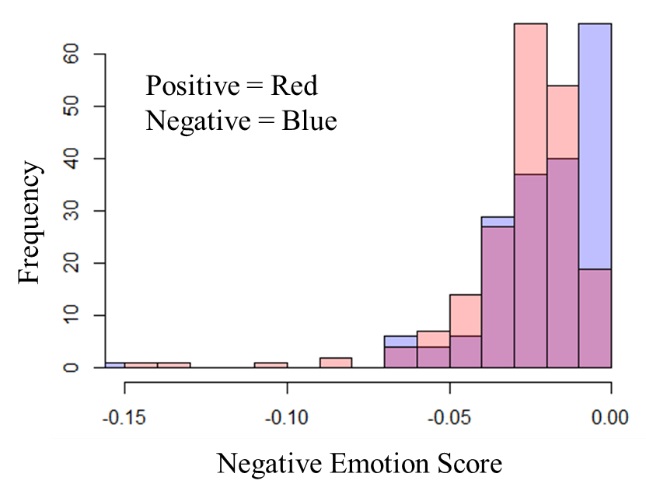
Figure 4. Histogram showing the difference in the distribution of emotion score (Top) and negative emotion score (Bottom) between positive and control post bodies (left) and titles (right).
As mentioned before, the polarity and subjectivity of posts can provide information regarding their state of the mind. The MPQA lexicon provides information regarding polarity (negative or positive) and subjectivity (strong or weak). To compute the scores, words associated with negative polarity are assigned a score of -1 and those with positive polarity are assigned a score of +1. Similarly, for weak subjectivity score (-1) and strong subjectivity score (+1). A per-corpus score was computed by summing each of these values and then normalizing over the length of the corpus. As with emotion scores, this was performed on post titles and post bodies separately. This study was performed on 200 randomly selected users from each of the positive training set and the control training set (a total of 400 users).
Hence, the hypotheses studied in this section were:
Polarity scores are related to the possibility of a user posting in the SW subreddit.
Subjectivity scores are related to the possibility of a user posting in the SW subreddit.
Figure 5, shows the distribution difference of polarity and subjectivity scores between the positive and control post body and title corpora. Statistical t-test results are as following:
Polarity for post bodies : p-value = 0.0836
Polarity for post titles : p-value = 0.1469
Subjectivity for post bodies : p-value = 0.8663
Subjectivity for post titles : p-value = 0.1219
Overall, we can see that all p-values are greater than 0.05 significance coefficient. Therefore, both null hypotheses were retained based on the analysis we performed, which suggests that polarity and subjectivity scores could not be used as features for supervised classification.
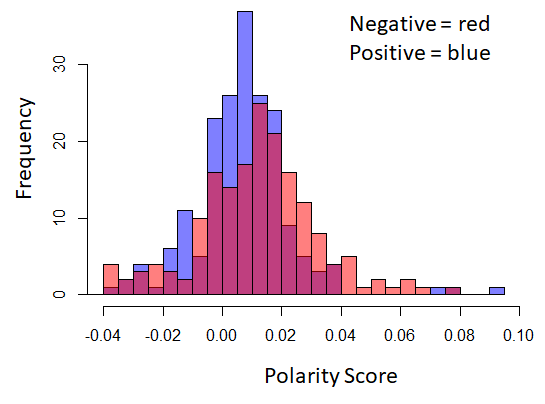
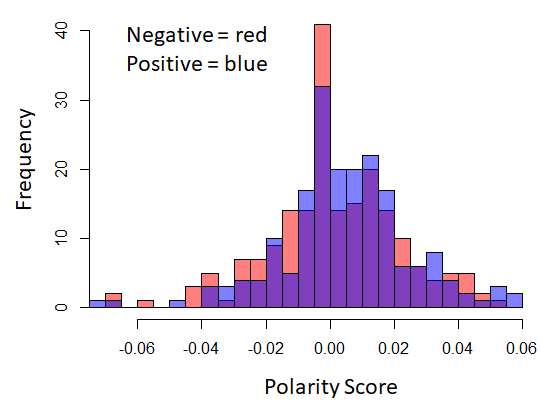
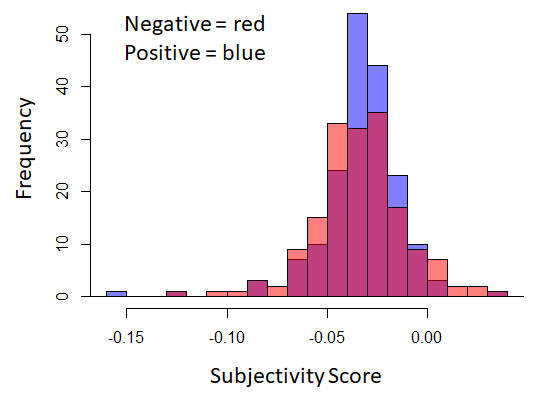
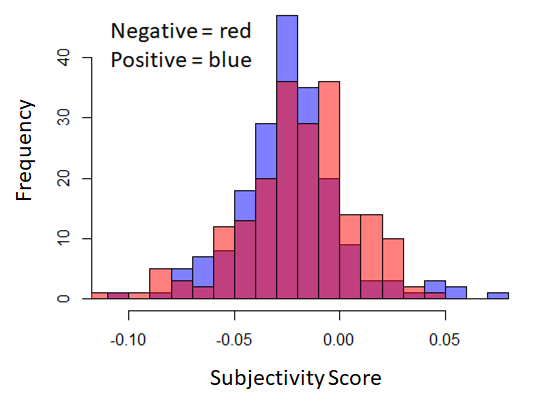
Figure 5. Histogram showing the difference in the distribution of polarity score (Top) and subjectivity score (Bottom) between positive and control post bodies (left) and titles (right).
Pronoun Analysis
It was suggested by (Mowery et. al. 2017 and De Choudhary et. al. 2016) that the focus on self (increased use of “I”) can be viewed as a feature in supervised classification. Hence, the hypothesis is that the use of first-person pronouns is increased in the posts by users who are more likely to post in Suicide Watch subreddit. To do this, a list of pronouns were gathered manually as follows:
First Person Pronouns = ['i', 'me', 'myself', 'mine', 'my', 'we', 'us', 'our', 'ours', 'ourselves']
Other Pronouns = ['you', 'yours', 'your', 'yourself', 'yourselves', 'he', 'she', 'his', 'her', 'hers', 'himself', 'herself', 'they', 'them', 'their', 'theirs', 'it', 'its', 'themselves', 'itself']
Using these manually selected pronouns, the number of first-person pronouns and the total number of pronouns were calculated in a given corpus and a first-person score was determined as follows:
First-person score = Number of 1st person pronouns / Total number of pronouns
For this analysis, no stopword filtration was used, since most of the pronouns would otherwise be considered stopwords. Figure 6, shows the histogram of first-person score distribution computed for 1000 positive and 1000 control user corpora. As it can be seen the distribution of positives and controls are very similar. Since the distribution is nonnormal Wilcoxon rank sum test was performed, which gives a p-value = 0.003. Although p-value is lower than significance coefficient = 0.05, however, looking at distributions, no significant difference can be observed, and furthermore, the p-value is not significantly lower than 0.05 (based on comparison with p-values of other features showing a significant difference between distributions). Therefore, although we can reject the null hypothesis, based on the observation, it was decided not to use first person score as a feature in supervised classification.
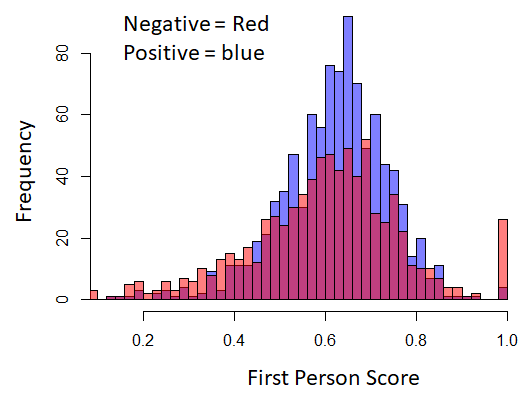
Figure 6. Histogram of first-person score between randomly selected positive and controls (negative) posts.
LDA Topic Modeling
Topic modeling provides a fairly general way of capturing thematic content or trends, which can be relevant for classification tasks. in this study, LDA (Latent Dirichlet Allocation) topic modeling was performed via the Gensim package for Python. For LDA training, a corpus of mixed positive and control posts from 2000 users (1000 positives and 1000 controls) was used.
Topic modeling with a number of topics ranging from 5 to 20 was considered for this study. User corpus was prepared by concatenating post bodies for each user, then tokenizing and removing stop words, and lastly, stemming the tokenized corpora using Porter stemmer from NLTK package. A dictionary of all training and dev set was formed by combining all the corpora together and creating a bag of words for each user corpus. Then those bag of words were used to train the LDA topic modeling. Another corpus of 40 positives and 40 controls from the Dev set was prepared to analyze the topic prediction on these 80 samples. Experimenting with a number of topics, 5 found to be too coarse and hence 20 topics were chosen for analysis. Figure 7, shows the probability distribution for each topic for positives and controls posts.
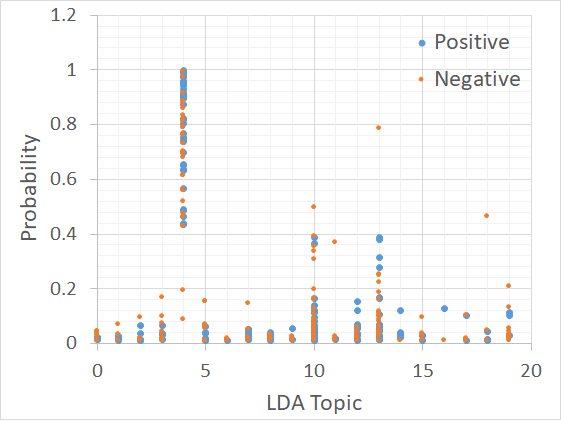
Figure 7. The probability distribution for 20 topics (identified by LDA modeling) over the sampled development set.
As it can be seen there exist differences between the probability distribution of certain topics, for example, we can point out to topics 2, 3, 5, 9, 14, 16, and 19. To gain better insight regarding the differences between topics, following are the top 20 words scored for each topic:
- fire wind san counti mph weather temperatur acr record low day mountain fell area high humid diego amp contain gust
- time lead fight http experi realli mind away well everi hear train song win amaz blow one sooth 1 may
- cup 1 add jello water 1/2 boil stir dissolv 1/4 oz 3 cold well shot fulli pour vodka cool 2
- one http 2 would like 1 game get use trade look x time number also two 3 play first make
- like get would know want go one time realli think make look thing feel peopl tri could use work even
- stream streamer minut anyon http » game everi giveaway chat win drizzal ghoul 10 receiv come fun better chanc drizzcoin
- run lad gonzalez- averag adrian strikeout base home pitch op walk royal record whip stolen cardin 1 total tiger cin
- enemi god damag assazz1n d3v1lz cost power mana second abil magic gt attack health cd target within passiv ult 3
- lt gt use get one new http peopl like 0 end work damag public file amp 1 see sub look
- 1x kill command drop 2x skill zilyana point dragon least saradomin gener experi black forc call http ink level graardor
- http gt would use get like one amp need 44 want work go look game know time also make 2
- min allow heal server -**server 15 5 ip start head info host gb allowed**stalk philidelphia use length off**neth pa find
- http **31** game 2 use would get play amp hero male 00 x card like deck 1 video newegg could
- like would http peopl get one think time go know make want use thing could game look someth year amp
- amp nbsp look get love like pick type bodi would will im sonicmeatwadd trade porn one kinki entertain nofap ”
- coil mod vape rda http instal postcard thank juic purchas cap clone voltag ohm card poem sacramento price favourit atti
- à en pharmaci rx onlin gener gt lt br de génériqu m.d buy price prescript cher lign approv purchas order
- failfish ledditw gt http level 1 fuck sheever get uncraft like look need cssbr amp team want href= 2 also
- sephora draven jim gt riot sivir rp opi purchas ohm yeah sam mission headphon 8-bit 8320 ecommerc key 32 reel
- game http play 1 2 level get ref like vintag ref* would key backpack.tf 3 buy team want know time
As it can be seen, class 4 which has the highest probabilities, can be classified as a collection of verbs which is present in most corpora, and hence majority have their highest probability as topic 4. Therefore, this topic does not provide any information regarding the state of the mind of the writer. Topic 2 which is the first topic showing the difference in probability distribution among the positive and negative posts can be viewed as drinking habits, which indicated posts having more words regarded about drinking habits would more likely to be among positives. Topic 3 can be viewed as playing and gaming which suggests postings having more words on this topic are less likely to be positives. Topic 5 can be viewed as internet activities with higher probabilities suggests less likeliness of being positive. Topic 9, has more words in violence, and hence a higher probability suggests the post is more likely to be positive. Topic 14, can be viewed as emotions, and hence related to a higher probability of being positive. Topic 16 seems to be related to drugs and pharmacy and therefore would suggest a higher probability of positive post. Topic 19, seems to be related to video games and suggests less likeliness of being a positive post. The analysis provided above shows that LDA topic modeling can be used as a feature set for supervised training, as differences between randomly selected positive and control posts can be observed.
Posts before and after Suicide Watch Post
In order to create a corpus for training, it is important to know if the state of the mind of the user changes before and after posting in the SW subreddit. If the state of mind changes, then we need to restrict our analysis to the posts made prior to any posts within SW. For this analysis, the average KL Divergence similarity between the posts before and after a user’s first SW post was analyzed. Therefore, 1000 users were selected randomly from the positive training set, and D(avg) was calculated for the LIWC word class representation of the corpora. Figure 8 shows the average KL Divergence similarity computed between the corpus of posts before and after the initial SW post. As it can be seen, the similarity between before and after posts is very high, and only a negligible amount of posts show a moderate to high level of dissimilarity. Therefore, it can be concluded that no filtering of the posts after the initial post in SW is necessary, as with high confidence it can be said that the state of mind remains unchanged.
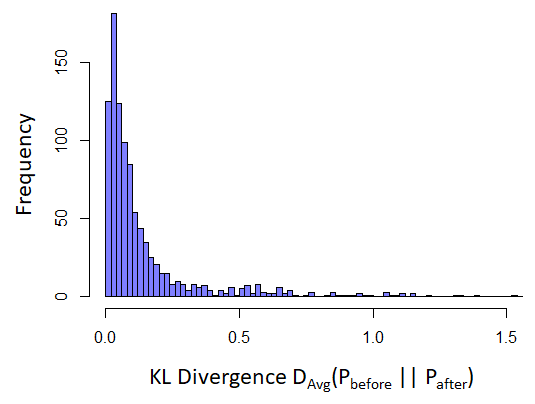
Figure 8. Histogram of averaged KL Divergence between posts posted before and after the Suicide Watch post. The lower number of KL Divergence indicates higher similarity.
Supervised Classification
For supervised classification, various classifiers from the NLTK and Scikit Learn packages (NLTK wrapper for Scikit Learn) were considered. These classifiers include the Naive Bayes classifier, Decision Tree classifier, Maximum Entropy classifier (with 100 iterations), and Linear Support Vector Classification (SVC) from SciKit Learn’s Support Vector Machine implementation (SVM).
Baseline
For the baseline, the word-level unigram language model was used to train various classifiers. From classification results (on test set), a confusion matrix was constructed for computation of accuracy, precision, recall, and F-Measure. The baseline classification statistics are presented in Fig. 9.
As can be seen from the figure, except for Maximum Entropy, the accuracy is relatively similar (~ 67%), with SVM and Decision Tree classifiers being the top performers since the F-measures (62% and 65%, respectively) are better than the Naive Bayes classifier (59%).
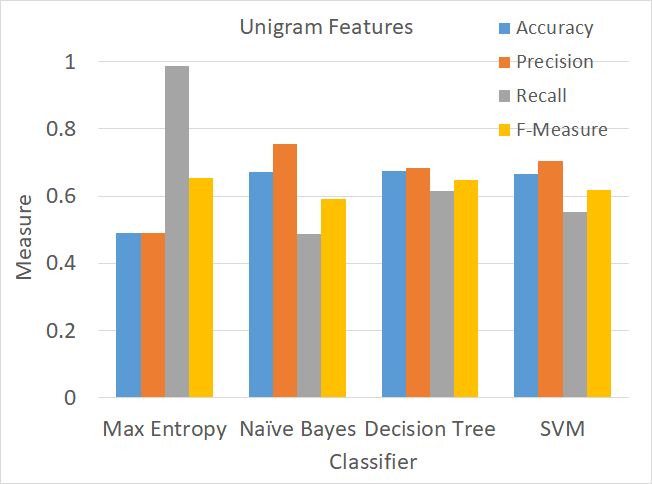
Figure 9. Measures of accuracy, precision, recall, and F-Measure for four supervised classifiers used to train on the unigram feature set.
Word Class Feature Set
In order to generate word class unigram features, each word was substituted with its corresponding class(es), and from this, a corpus of word classes was created for each user. Different classifiers were used to train on the unigram-type feature of word classes. The results of classifier performances using only this feature are shown in Fig. 10. As it can be seen, an increase in performance is apparent in all four classifiers. The Naive Bayes classifier does not see much improvement in accuracy, however, the F-measure has increased to 72% (compared with the baseline’s 59%). The Maximum Entropy classifier sees a remarkable increase to 72% accuracy and 74% F-measure (compared with the baseline Maximum Entropy performance of 49% accuracy and 65% F-measure). The top-performing classifiers are Decision Tree (accuracy of 73% and F-measure of 72%) and SVM (accuracy of 73% and F-measure of 75%), which show an improvement over 5% in accuracy and 10% in F-measure compared with their respective baseline performances.
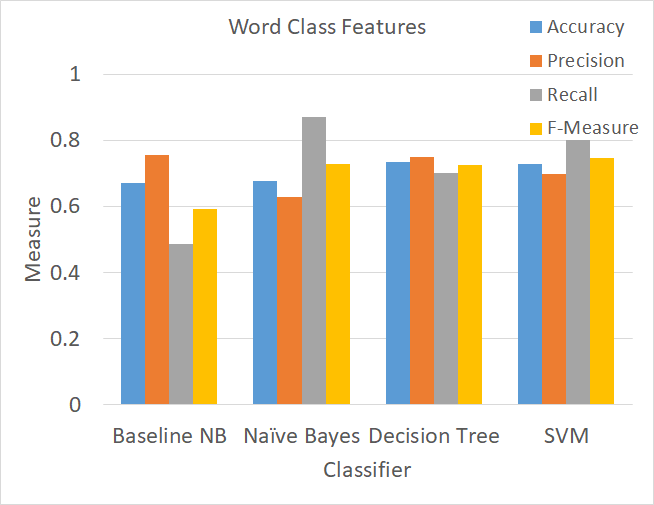
Figure 10. Measures of accuracy, precision, recall, and F-Measure for four supervised classifiers used to train on the LIWC word class unigram feature set.
Emotion scores include NEGEMO, POSEMO, and EMOSCORE (which is the difference between NEGEMO and POSEMO), as explained earlier. Therefore, for this part, three features were created, and emotion scores were calculated for each user. Then, a total of ten buckets of emotion scores were used for classification training. The classifier’s performance using only emotion scores are shown in Fig. 11. Results show marginal accuracy improvement (~68% for all classifiers) and considerable F-Measure improvement (~70% for all classifiers) over the baseline, which indicates, this feature performs better than the baseline unigram.
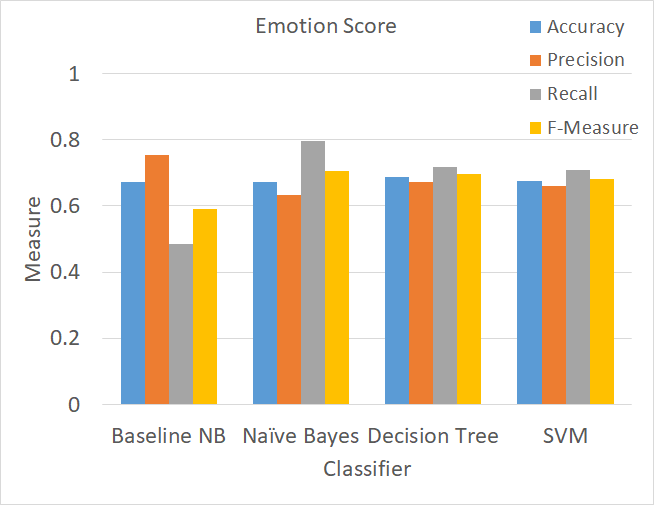
Figure 11. Measures of accuracy, precision, recall, and F-Measure for four supervised classifiers used to train on LIWC emotion scores feature set.
LDA Topics Feature Set
To generate LDA topic features, the training set was first used to train a handful of LDA topic distributions. Then, features were generated based on the topic predictions and their probability for each user. The probabilities were divided into 20 buckets, which represent the value of each LDA topic. Figure 12, shows various classifier performances using only the LDA topic features.
As it can be seen the classifiers performances compared with their respective baseline are improved marginally. The accuracy is 57% for Maximum Entropy (improved from 49%), 67% for Naive Bayes (no improvement), 66% for Decision Tree (reduced by 1%), and 69% for SVM (improved by 2%). The F-measures also show marginal improvements to 66% for Maximum entropy and 69 - 70% for other 3 classifiers.
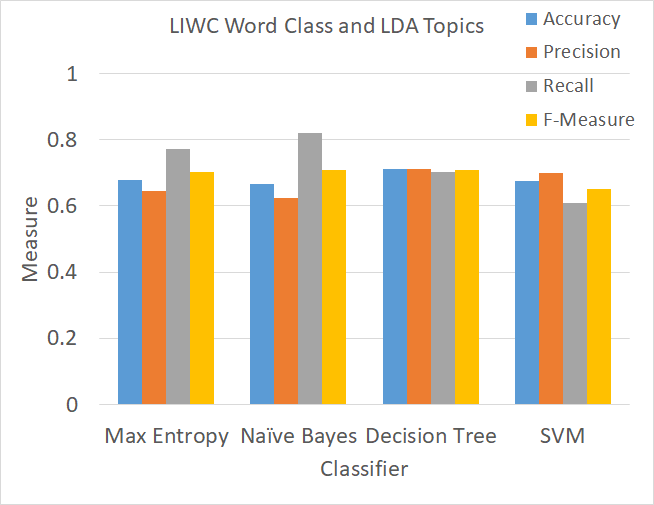
Figure 12. Measures of accuracy, precision, recall, and F-Measure for 4 supervised classifiers used to train on LDA topic model predictions.
Combined Feature Sets
Finally, the performance of the four classifiers was compared using a combination of previously discussed feature sets. Looking at Fig. 13 shows that the performance of classifiers using combined feature sets is lower than their performance using only LIWC unigram word class representation feature set.
Therefore, this study revealed that the top performing feature is "unigram classification on LIWC lexicon representation" which leads to the highest accuracy (73%) and F-measure (74%). Other features studied in this work, perform in between baseline and LIWC lexicon representation. Combining features in classifiers did not yield any improvement. One reason for such behavior can be due to the training, development, and test sets being unclean, as some posts which are not really positive are classified as positive.
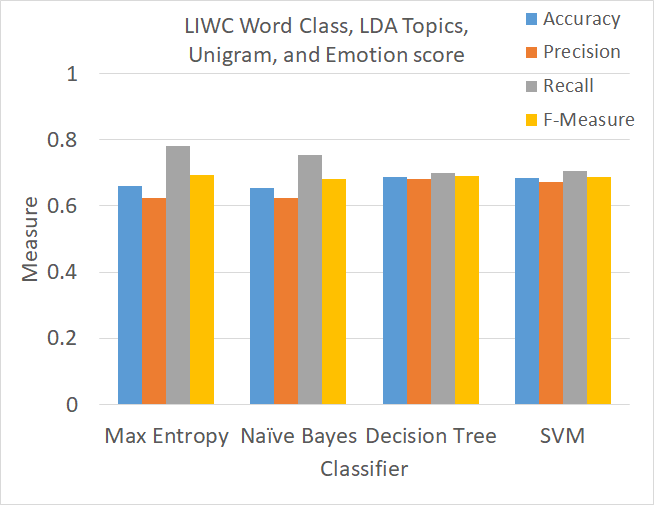
Figure 13. Measures of accuracy, precision, recall, and F-Measure for four supervised classifiers used to train on LDA topic model predictions, LIWC unigram word class representation, emotion score, and baseline unigram feature sets.
Future Work
In many instances while looking at the data, there are posts in Suicide Watch which are not aimed at the user being in a suicide state, but rather, advertising a treatment, or just trying to calm other users. Having such posts (and users) in training, development, and test sets reduce the performance greatly, as the classifier might classify such posts correctly but being in the positive corpus, penalizes the prediction. Therefore, a great future work would clean up the sets.
Another semi-automatic route that can be suggested to clean up the data, is to use the similarity scores between positive and control posts. However, due to the large amount of data and O(n^2) user to user comparisons needed, this task was not completed in this study. However, in Fig. 1, which is the heat map of similarity between few positive and control users, already shows the advantage of this route and can provide a faster method (compared to manual filtering) for filtering the data.
Another suggestion for future work will be using more sophisticated classifiers such as ensemble classifier or neural network approaches. Upon having clean data, such classifiers can out-perform the classifiers used in the current study.
References
- [Coppersmith et al. 2015] Coppersmith, G., Leary, R., Whyne, E., and Wood, T. Quantifying suicidal ideation via language usage on social media.
- [De Choudhury et al., 2016] De Choudhury, M., Kiciman, E., Dredze, M., Coppersmith, G., and Kumar, M. (2016). Discovering shifts to suicidal ideation from mental health content in social media. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, pages 2098-2110. ACM.
- [Milne et al., 2016] Milne, D. N., Pink, G., Hachey, B., and Calvo, R. A. (2016). Clpsych 2016 shared task: Triaging content in online peer-support forums. In Proceedings of the Third Workshop on Computational Linguistics and Clinical Psychology, pages 118-127, San Diego, CA, USA. Association for Computational Linguistics.
- [Mowery et al., 2017] Mowery, D., Smith, H., Cheney, T., Stoddard, G., Coppersmith, G., Bryan, C., and Conway, M. (2017). Understanding depressive symptoms and psychosocial stressors on twitter: A corpus based study. Journal of Medical Internet Research, 19(2).